


At this point it’s fairly safe to assume that most everyone in the business of “data” has heard of the European Union (EU)-wide General Data Protection Regulation (GDPR) that was signed into law in late April 2016; with the compliance deadline having come into effect on May 25, 2018.
Clearly, this new regulation has significant implications for organizations across the globe as it relates to data capture, storage, transfer and use. In previous blogs, whitepapers, and webinars, we outlined various ways by which companies can either “get started” with their GDPR compliance efforts, and also how to “maintain” compliance over the long-term.
With all the focus on GDPR compliance, however, we may have glossed over the importance of executing some key data processes for purposes much broader than GDPR. So, let’s forget about GDPR – only for a moment – and level-set on a few critical steps organizations must take to protect their sensitive data, mitigate the risk of accidental or malicious exposures and the subsequent cost and reputational risk.
A major challenge, and one that goes well beyond privacy compliance
In the rush to meet industry expectations or compliance cut-off dates, organizations may skip some foundational steps critical to ensuring long-term data security and reducing organizational cost and administrative burden. Far too many organizations spend far too much money trying to prevent data breaches by simply throwing the full force of technology at their environments. And, just like the old saying “half the money I spend on advertising is wasted; the trouble is I don’t know which half,” half the money spent on data protection is likely also wasted.
To that end, you can’t protect what you don’t know about. Many organizations labor under a false sense of security with respect to knowing what data they have, and where, and that’s just their production data environments. In many cases, lower level non-production or DevOps environments are similar to “wild west” organizational data stores with multiple copies, users, and risk points, usually with fewer security controls in place. In fact, according to an IDC report titled “Copy Data Management”, 82% of organizations surveyed had more than 10 copies of each database, a number that’s no doubt growing as data capture, storage, and use continues to grow.
Furthermore, organizations can waste a lot of time and money on a multitude of unnecessary technologies and resources aimed at protecting complex yet unclassified data environments. Understanding where all your data is stored, classifying relevant sensitive data to align with security and privacy requirements, and assessing vulnerabilities all play a critical role in priming the organization for long-term data security success; and in supporting process and technology enhancements in a more strategic and cost-effective manner.
This leads me to offer what many believe to the number one data security priority for any organization, regardless of industry compliance requirements. That is, data discovery and classification.
Executing your number one data security priority could also save you millions.
By identifying all databases, including archived, forgotten or rogue databases (yes, these exist!), cataloguing and classifying sensitive data, and assessing databases for vulnerabilities and misconfigurations; your organization is in a much better position to make educated decisions on what investments need to be made, and where, in terms of data security. It also allows you to find weak points in the chain, and make decisions on what data is being captured, why, and where opportunities exist to remove databases/sensitive data, ultimately limiting risk footprint and overall data protection costs.
Too many high profile, high value organizations skip this critical step in the haste to tick the compliance checkbox and are therefore under the false assumption that they are protected against the cost of data breach because they have either (a) purchased and installed various security software and related applications, and/or (b) have grossly inflated their IT budgets with additional internal hires or an army of consultants. They don’t really know what they have, where it is, or why they are protecting it (and at what cost).
This is clearly a risky scenario from a variety of perspectives. So, where do you go from here? Some organizations attempt manual discovery efforts to achieve a greater understanding of their data environments, and while better than nothing, these manual processes are fraught with inefficiencies, risk, and opportunity costs when looking at the resources required.
Leveraging industry-recognized, purpose-built solutions and expertise offer a much more efficient and effective way to conduct data discovery and classification and offers a more scalable and sustainable process over the long-term. Imperva offers a variety of data security solutions and managed services to support organizational data discovery and classification efforts, with the two solutions being Imperva SecureSphere and Imperva Camouflage.
Mapping your data landscape with Imperva Data Security solutions
The Imperva SecureSphere solution offers Discovery and Assessment, which provides an automated and reliable way to locate ALL sensitive data. It easily identifies where databases are on the network, and across complex environments. It also surfaces rogue databases and finds sensitive data pertinent to all major privacy and compliance regulations. In addition, SecureSphere also streamlines vulnerability assessment at the data level. It provides a comprehensive list of over 1500 tests and assessment policies for scanning platform, software, and configuration vulnerabilities.
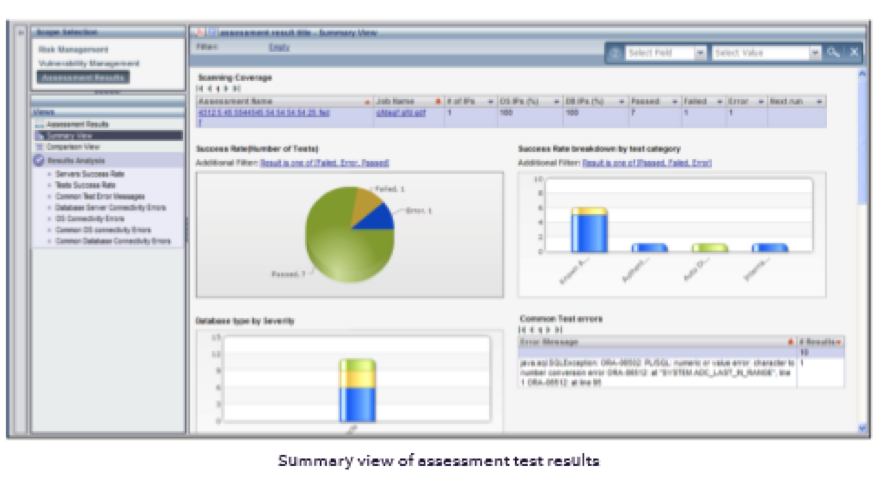
To make life even easier, SecureSphere produces automated and detailed reports that help provide an understanding of an organization’s overall security posture and risk footprint. In addition to graphical dashboards, it includes pre-defined assessment test reports as well as the ability to create custom reports. Assessment test reports also provide concrete recommendations to mitigate identified vulnerabilities and strengthen the security posture of a data repository. With respect to Imperva Camouflage, it too offers discovery and classification capabilities embedded within this purpose-built data masking solution, and many organizations avail of its discovery and classification capabilities when choosing to de-identify or mask their sensitive data for use in securing DevOps or test and development data use.
Regardless of the solution, it’s clear that using a purpose-built tool, with years of expertise built right-in can provide significant value to an organization when compared to native or manual efforts, and helps ensure a long-term sustainable model for data security.
The ease with which you can achieve critical data security outcomes provides significant value to the organization and a compelling cost/benefit analysis for the ultimate decision makers. These outcomes include:
- Uncovering new, forgotten or rogue databases
- Discovering where sensitive data is stored across your database infrastructure
- Detecting database vulnerabilities based on the latest research from the Imperva Defense Center
- Automating database discovery, sensitive data classification, and database vulnerability assessment • Audit database configurations and measure compliance with industry standards
- Streamlining regulatory compliance efforts
Armed with this information an organization can quickly identify the level of security required for each application/database and determine both the appropriate technologies as well as the priority of deployment and investment required.
Ultimately, the organization will be primed to reduce their risk of internal or external data breaches, while at the same time enabling secure data use and copy provisioning. Oh, and let’s not forget the value in supporting compliance with privacy regulations such as HIPAA, FERPA, and GDPR!
Contact us to learn more about Imperva’s data security solutions and managed discovery and classification managed services in detail. Also, feel free to test-drive SCUBA, our free database vulnerability scanner tool, and/or CLASSIFIER, our free data classification tool.
Try Imperva for Free
Protect your business for 30 days on Imperva.










