





In one software development project after another, it has been proven that testing saves time. Does this hold true for machine learning projects? Should data scientists write tests? Will it make their work better and/or faster? We believe the answer is YES!
In this post we describe a full development and deployment flow that speeds up data science work, raises data scientist confidence levels and assures quality of delivery – just like in software development.
Read more to learn about our testing methodology in data science projects, including examples for tests in the different steps of the process.
Testing Methodology – Flow
As in many ML projects, we assume the following:
- A constant flow of data
- The ML model is created and delivered on a periodic basis, to account for training on new data
- Aspects of the model itself can change: features, hyper parameters or even the algorithm
We divide the tests into two main types:
| Description | Environment | |
| Pipeline tests | Test model creation process | Test environment, with test data |
| ML tests | Validate the created model’s performance/accuracy | Production environment, updated data |
Below is a diagram of the full flow of our suggested methodology. The flow can be triggered by one of two events:
- A periodic model creation: if the only thing that changes is the data, run only ML tests.
- Pipeline update: any change to data, model hyper parameters, etc. Run Pipeline tests and ML tests.
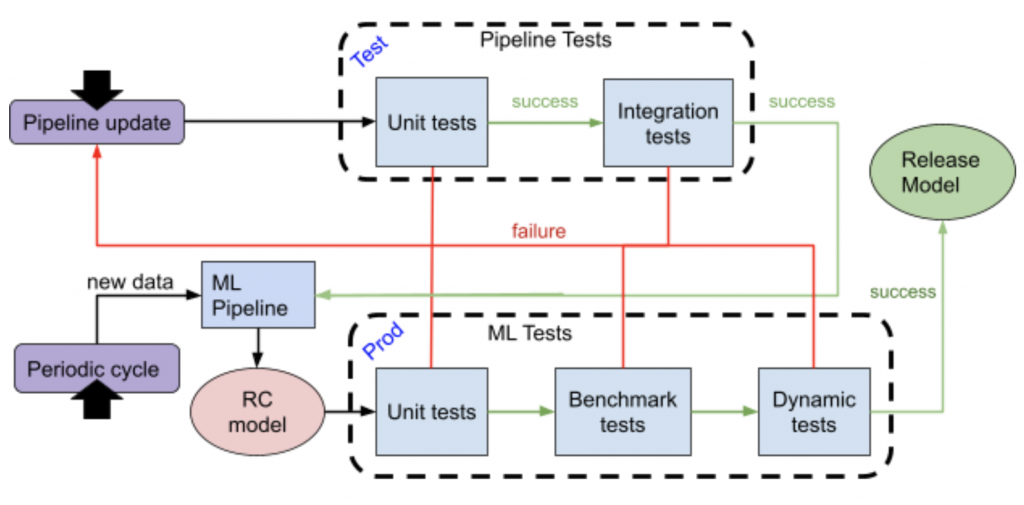
On success, the model’s Release Candidates (RC) can be deployed to production. On failure, the code should be fixed and the entire test pipeline run again.
Read more to learn about the flow and the different kinds of tests we run.
Testing Methodology – Steps
ML Pipeline Tests
ML Pipeline unit tests
Unit tests are just as relevant to machine learning pipelines as to any other piece of code.
Every step of the pipeline can, and should, be tested by a unit test.
The machine learning pipeline is based on code. Functionality includes many steps like:
- Querying data
- Processing data and feature extraction
- Training and testing the model
- Performing inference
- Calculating metrics
- Formatting and saving results
Pipelines change from one to another in the steps but all are based on code, and the code must be tested – even if it is written by data scientists.
Example:
A unit test to test the feature calculation that counts the number of SQL keywords in the HTTP request url:
def test_keywords_count():
# there is a global list of keywords: [‘text’, ‘word’, ‘sentence’]
assert extract_keywords(“text with a keywords”) == 1ML Pipeline integration tests
The flow of data is (hopefully) saved in an external data source like a database or an object store and not on your local disk.
To fully test your pipeline functionality, you will have to access external sources and might need to provide credentials for running such tests.
There are two approaches to test external access functionalities:
- Test DB with a test data set
- Mock DB (or other external source)
We recommend using both integration tests and mocks. Some data sources are really hard to mock and it will be easier to use a test environment – it really depends on the data source and the process you are trying to test.
We recommend running an end-to-end pipeline flow on a test environment with some test data – to make sure the flow works with an actual data source.
Here is an example from our ML pipeline infrastructure – we load sample data from a test database, process it and split it to train and test datasets. Later we run, train and test:
pipeline.load_data(records_limit=1_000)
pipeline.process_data(train_test_split=0.2)
pipeline.train()
pipeline.test()
Machine Learning tests
Unlike pipeline tests, where we want to check that the model creation doesn’t fail, – in ML Tests we get a trained model as an input which results we want to evaluate.
Each section can test different use cases. Debugging ML models is difficult but if you choose your tests wisely, you will be able to progress faster and, in case of degradation, be able to quickly analyze what went wrong.
Pipeline and tests example
For our examples we will use an ‘SQL Injection’ classifier. The classifier gets an HTTP request as the input, and outputs the probability for an SQL Injection attack:

The HTTP request is first transformed to a feature vector, and then sent to the model.
Here are some feature examples which are common in SQL injection attacks:
- SQL Keywords like SELECT, UNION and more
- SQL characters like single quote, dash, backslash and more
- Tautology expressions like ‘1=1’ and more
HTTP request feature vectors may look like:
| SQL Keywords | SQL Characters | ||||
| SELECT | UNION | UNION ALL | Single quote | equals | … |
| true | false | false | 2 | 0 | |
| false | false | false | 0 | 0 | |
| false | false | false | 0 | 1 | |
We will use this example to explain the following ML test types.
ML “Unit Tests”
Programmers write unit tests for very specific inputs, such as exceptional inputs or inputs added as a test after a bug is found. We believe data scientists should do the same.
We want to make sure obvious input will be classified correctly, and fail the testing process fast if it doesn’t. We can also require certain confidence in the prediction, e.g the prediction is higher than 0.7. These are qualitative accurate tests that can test a single record or a small data set.
Example:
A URL with OR 1=1 value in a parameter must be classified as an attack
We used pytest to run the ML testing, here is what a simple test looks like:
def test_1_equals_1():
result = inference_record(url="/my-site?name=OR 1=1")
assert result.is_attack == True
assert result.attack_probability >= 0.7Note that in the inference_record() function we send partial data. The function accepts only the URL and the rest of the data is generated automatically as described below. In unit testing, the use case we describe (e.g. URL contains “1=1”) should be so obvious, the rest of the data should not change the prediction.
The rest of the data is generated automatically. There are three possible approaches:
- Create a ‘default’ input record, or a set of them. The default values should be neutral in the sense they should not influence the prediction much.
- A small well-shuffled sample from your data and change only the values you test.
- Generate a set ‘average’ input record. Use statistics over existing data to find the most common and neutral values for each column.
Here is another example in which we used the prediction feature contribution. There are several ways to get a prediction’s features contribution. A very popular way is SHAP, which is model agnostic. In this test we check that the UNION ALL feature contributed to the attack probability:
def test_union_all_keyword():
result = inference_record(url="/my-site?name=UNION ALL")
assert ”union_all” in result.contributions
assert result.contributions[”union_all”] >= 0.1Benchmark Tests
Benchmarking is our way to know the model performance is at least as good as it used to be. The benchmark tests are based on a group of static data sets. To pass the benchmark tests, the model must perform at least as well as some predefined metrics (e.g., accuracy higher than 0.95 and precision higher than 0.97).
The benchmark tests should be created as early as possible in the project, and they will not change (though, of course, you can add new data sets to the benchmark!). They can include:
- Data sets that represent real life data to the best of your abilities; and
- Realistic and common scenarios.
The benchmark tests will be run on every code change that was pushed, so any degradation will be noticed as soon as it is created.
Examples:
- Legitimate HTTP traffic – none of the requests should be classified as attacks
- Attack tools data sets – malicious tools data can be captured and saved to a data set
- Common attack vectors
def test_attack_samples():
result = inference_benchmark(”sqli_keywords.csv”)
assert (result[”prediction”] == 1).all()Dynamic Tests
A dynamic test is meant to test a specific scenario on changing data and is somewhat random. The most obvious choice is a running time frame – e.g. run today’s test on the week prior to the test date. By running tests on different days, you will be able to notice changes in your model’s performance.
The use cases can be similar to the benchmark tests. Testing on different dates over time can help you monitor how well the model does on real life data and how its performance changes. A degradation in the dynamic tests can mean two things:
- Your model is not as good as it used to be; or
- Reality changed.
Both options require the attention of a data scientist.
As opposed to benchmark tests, dynamic test data change on each test run. In some cases, you will not be able to get high quality labels. You might have to settle for some heuristics.
Dynamic test use cases can be a combination of the use cases from the benchmark tests and the unit tests.
Example:
Legitimate traffic changes all the time, and we want to make sure all of the requests are not identified as SQLi attacks.
def test_30d_back_clean_traffic():
result = inference_by_filter(days_back=30, is_attack= False)
assert (result[”prediction”] == 1).all()A vulnerability scanner is a tool made to identify weaknesses in a system. It sends many attacks, testing to see if they succeed.. The dynamic test below runs on HTTP requests, 90 days back, that are created by a vulnerability scanner.
There are many scanners, and new versions are released all the time, and that’s why we need a dynamic data set. We would like to make sure that the maximum number of requests originated by scanners are identified as attacks. In this example we assume the client application is known:
def test_90d_back_by_vulnerability_scanners():
result = inference_by_filter(days_back=90,
client_app=VulnerabilityScanner)
assert result.accuracy >= 0.99Since the input data is changed dynamically, we use thresholds to decide on a failure. Data that isn’t classified correctly is used later to improve pipeline – either the model or the pipeline may be updated.
Takeaway lesson
Testing saves time, even for data scientists. Include tests in your project and in your planning. It will help you in many ways – you will know where your model stands, you will be able to make changes with confidence, and you will deliver a more stable model with better quality.
The most basic tests we recommend to start with are:
- Pipeline integration tests – pipeline sanity test, including integration with a data source
- ML benchmark tests – static data sets, according to your domain subjects

Pick the tests that are most important to your work – the more the better!
Try Imperva for Free
Protect your business for 30 days on Imperva.

