


What is a Data Warehouse?
Organizations use data warehouses as a central repository. The warehouse is typically connected to multiple data streams, such as relational databases, transactional systems, and other sources. The data is typically kept in the warehouse for future use, but it can also be used for analysis purposes.
Several organizational roles work directly with the data warehouse. Data engineers ensure the data is ingested and processed correctly. Data scientists, business analysts, and data analysts access the data via BI (business intelligence) integrations and SQL clients, to extract relevant business insights and build reports and dashboards for decision makers.
Data warehouses provide a technical infrastructure to efficiently store structured data, and rapidly perform analysis on very large volumes of data across the enterprise. Data warehouses enable fast analysis for hundreds of users, who create, consume and interact with business reports and dashboards.
Data Warehouse Benefits
Data warehouses are a foundational data infrastructure that provides the following benefits:
- Consistent, high-quality data—data warehouses ingest data from a large number of disparate sources, cleans the data, standardizes it, and converts it to a format that enables fast and effective analysis.
- Faster insights—each individual data source is limited in its ability to support certain decisions. The data warehouse can easily combine and evaluate all relevant data sources, providing insights in near real time.
- Smarter decision-making—data warehouses support BI functions such as data mining (discovery of patterns and relationships in data), artificial intelligence, and machine learning. Data from the data warehouse can support decisions in almost every area of the organization, from business processes to financial management, operations and ERP, inventory management, sales and marketing.
What is the Difference: Data Warehouse vs Database
A database is a structured collection of data. Excel spreadsheets and address books are examples of very simple databases. Software such as Oracle, MySQL and MongoDB are database management systems (DBMS or RDBMS) that allows users to access and manage the data in a database. A data warehouse is also a type of database, but unlike a standard RDBMS, it focuses on the purpose of storing historical data from various sources and enabling fast analytics.
What is the Difference: Data Warehouse vs Data Lake
An important feature of databases and data warehouses is that they contain structured data. The data model, also known as a schema, is agreed in advance, and all data must comply with the same rules – for example, which fields are available, data formats and allowed values.
Data lakes are another way of storing data, but unlike data warehouses, they store data in object form, without a particular structure. The architecture of the data lake is based on queries – users can query the data based on metadata attached to each object. This makes a data lake less suitable for structured queries, and it requires sophistication to extract insights from the data. However, loading data into a data lake is very easy.
To summarize, a data warehouse is difficult to set up and requires expertise to ingest the data, but then makes it easy to run reports and generate insights. A data lake is the other way around – easy to move data in, more complex to query it and extract business insights.
How Does a Data Warehouse Work?
A typical data warehouse workflow involves three key steps: ETL, distribution of data to data marts, and BI analysis.
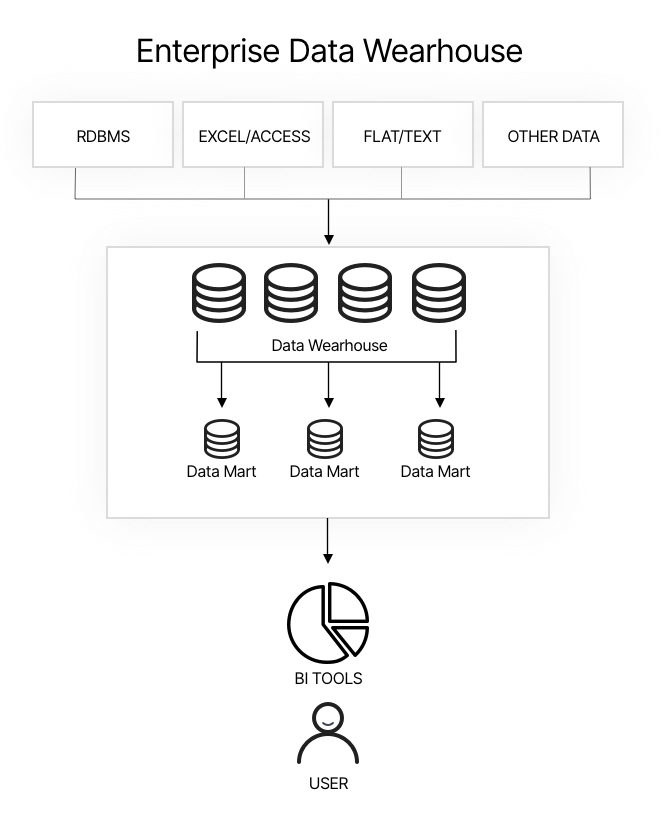
Extract Transform Load (ETL)
The ETL process is used to process data and ingest it into the data warehouse in the correct format. It is a systematic, automated method to integrate data from multiple systems and sources, and is an important part of an organization’s data integration toolkit.
For years, companies have relied on ETL processes to integrate data into one accurate dataset that enables them to make fast business decisions.
Data Mart
Once data is ingested into the data warehouse, it is passed to data marts. These are smaller units, holding a portion of the data in the data warehouse, which is intended for a specific division or department in the organization. For example, there might be a data mart for finance, sales, marketing, logistics, and human resources. Another possible division into data marts is according to customers, suppliers, or organizational business units.
Business Intelligence (BI) Tools
BI systems provide historical, current and forecasted views of business operations. They access data, either directly from the data warehouse or from a data mart. BI tools can provide live dashboards, periodic reports, pivot table and “slice and dice” analysis of multi dimensional data.
BI tools are designed to help organizations understand the huge amounts of data that accumulate over time, presenting data in a format that can be analyzed, and can guide decision making.
When data is stored in a data warehouse, BI tools can perform complex aggregations across multidimensional datasets, typically using the Online Analytical Processing (OLAP) standard. They can display data in multi-dimensional views, using the concept of OLAP cubes.
How to Implement an Enterprise Data Warehouse in the Cloud
Increasingly, companies are moving corporate data warehouses to the cloud, to eliminate the huge effort and cost involved in setting up and maintaining this infrastructure. All major cloud providers offer cloud data warehouse solutions – notably Amazon Redshift, Google BigQuery, and IBM DB2.
Below is a proposed four-step process for implementing an enterprise data warehouse to the cloud.
Workshop
The project starts by defining business use cases for the cloud data warehouse, and identifying metrics and KPIs to evaluate the success of the project. Collaborate with team members such as business analysts, BI developers, and database administrators to define the target metrics.
Assessment and Planning
List data sources and assign them to datasets, database tables, and other structures. Define the ETL process, and security mechanisms needed for governance and compliance. Put together a team that can help create the minimum viable product of the data warehouse.
Minimum Viable Product
Define a minimum configuration for the cloud data warehouse that can already provide value for the organization. The design should include all aspects of a production deployment, including connectivity, data routing, replication, access control and security. Prepare environments for development, testing, and production, build an initial data warehouse in development and as it matures, push it to testing and production, allowing organizational users to try it out.
Migration Phase
Finally, you can move on to the migration phase and migrate the entire dataset to the cloud data warehouse cloud platform. At this point, you can also implement a full ETL process to ensure consistency between local and cloud workloads. Finally, reconfigure BI tools to run against the cloud-based data warehouse.
Imperva Data Protection Solutions
Imperva provides a complete data security solution to protect your data wherever it lives—on premises, in the cloud and in hybrid environments. It also provides security and IT teams with full visibility into how the data is being accessed, used, and moved around the organization.
Our comprehensive approach relies on multiple layers of protection, including:
- Database firewall—blocks SQL injection and other threats, while evaluating for known vulnerabilities.
- User rights management—monitors data access and activities of privileged users to identify excessive, inappropriate, and unused privileges.
- Data masking and encryption—obfuscates sensitive data so it would be useless to the bad actor, even if somehow extracted.
- Data loss prevention (DLP)—inspects data in motion, at rest on servers, in cloud storage, or on endpoint devices.
- User behavior analytics—establishes baselines of data access behavior, uses machine learning to detect and alert on abnormal and potentially risky activity.
- Data discovery and classification—reveals the location, volume, and context of data on premises and in the cloud.
- Database activity monitoring—monitors relational databases, data warehouses, big data and mainframes to generate real-time alerts on policy violations.
- Alert prioritization—Imperva uses AI and machine learning technology to look across the stream of security events and prioritize the ones that matter most.

