


What is web scraping
Web scraping is the process of using bots to extract content and data from a website.
Unlike screen scraping, which only copies pixels displayed onscreen, web scraping extracts underlying HTML code and, with it, data stored in a database. The scraper can then replicate entire website content elsewhere.
Web scraping is used in a variety of digital businesses that rely on data harvesting. Legitimate use cases include:
- Search engine bots crawling a site, analyzing its content and then ranking it.
- Price comparison sites deploying bots to auto-fetch prices and product descriptions for allied seller websites.
- Market research companies using scrapers to pull data from forums and social media (e.g., for sentiment analysis).
Web scraping is also used for illegal purposes, including the undercutting of prices and the theft of copyrighted content. An online entity targeted by a scraper can suffer severe financial losses, especially if it’s a business strongly relying on competitive pricing models or deals in content distribution.
Scraper tools and bots
Web scraping tools are software (i.e., bots) programmed to sift through databases and extract information. A variety of bot types are used, many being fully customizable to:
- Recognize unique HTML site structures
- Extract and transform content
- Store scraped data
- Extract data from APIs
Since all scraping bots have the same purpose—to access site data—it can be difficult to distinguish between legitimate and malicious bots.
That said, several key differences help distinguish between the two.
- Legitimate bots are identified with the organization for which they scrape. For example, Googlebot identifies itself in its HTTP header as belonging to Google. Malicious bots, conversely, impersonate legitimate traffic by creating a false HTTP user agent.
- Legitimate bots abide a site’s robot.txt file, which lists those pages a bot is permitted to access and those it cannot. Malicious scrapers, on the other hand, crawl the website regardless of what the site operator has allowed.
Resources needed to run web scraper bots are substantial—so much so that legitimate scraping bot operators heavily invest in servers to process the vast amount of data being extracted.
A perpetrator, lacking such a budget, often resorts to using a botnet—geographically dispersed computers, infected with the same malware and controlled from a central location. Individual botnet computer owners are unaware of their participation. The combined power of the infected systems enables large scale scraping of many different websites by the perpetrator.
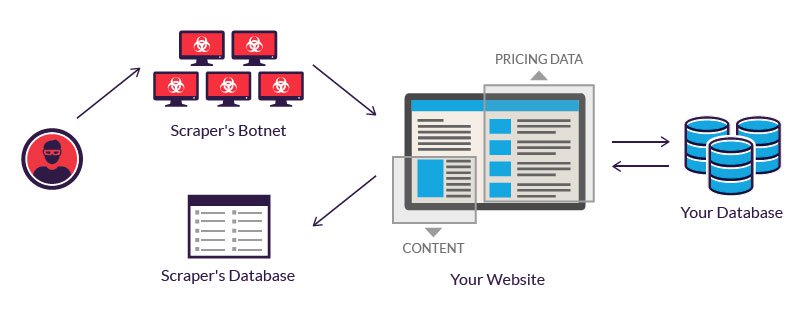
Malicious web scraping examples
Web scraping is considered malicious when data is extracted without the permission of website owners. The two most common use cases are price scraping and content theft.
Price scraping
In price scraping, a perpetrator typically uses a botnet from which to launch scraper bots to inspect competing business databases. The goal is to access pricing information, undercut rivals and boost sales.
Attacks frequently occur in industries where products are easily comparable and price plays a major role in purchasing decisions. Victims of price scraping can include travel agencies, ticket sellers and online electronics vendors.
For example, smartphone e-traders, who sell similar products for relatively consistent prices, are frequent targets. To remain competitive, they’re motivated to offer the best prices possible, since customers usually go for the lowest cost offering. To gain an edge, a vendor can use a bot to continuously scrape his competitors’ websites and instantly update his own prices accordingly.
For perpetrators, a successful price scraping can result in their offers being prominently featured on comparison websites—used by customers for both research and purchasing. Meanwhile, scraped sites often experience customer and revenue losses.
Content scraping
Content scraping comprises large-scale content theft from a given site. Typical targets include online product catalogs and websites relying on digital content to drive business. For these enterprises, a content scraping attack can be devastating.
For example, online local business directories invest significant amounts of time, money and energy constructing their database content. Scraping can result in it all being released into the wild, used in spamming campaigns or resold to competitors. Any of these events are likely to impact a business’ bottom line and its daily operations.
The following is excerpted from a complaint, filed by Craigslist, detailing its experience with content scraping. It reinforces how damaging the practice can be:
“[The content scraping service] would, on a daily basis, send an army of digital robots to craigslist to copy and download the full text of millions of craigslist user ads. [The service] then indiscriminately made those misappropriated listings available—through its so-called ‘data feed’—to any company that wanted to use them, for any purpose. Some such ‘customers’ paid as much as $20,000 per month for that content…”
According to the claim, scraped data was used for spam and email fraud, among other activities:
“[The defendants] then harvest craigslist users’ contact information from that database, and initiate many thousands of electronic mail messages per day to the addresses harvested from craigslist servers…. [The messages] contain misleading subject lines and content in the body of the spam messages, designed to trick craigslist users into switching from using craigslist’s services to using [the defenders’] service…”
Web scraping protection
The increased sophistication in malicious scraper bots has rendered some common security measures ineffective. For example, headless browser bots can masquerade as humans as they fly under the radar of most mitigation solutions.
To counter advances made by malicious bot operators, Imperva uses granular traffic analysis. It ensures that all traffic coming to your site, human and bot alike, is completely legitimate.
The process involves the cross verification of factors, including:
- HTML fingerprint – The filtering process starts with a granular inspection of HTML headers. These can provide clues as to whether a visitor is a human or bot, and malicious or safe. Header signatures are compared against a constantly updated database of over 10 million known variants.
- IP reputation – We collect IP data from all attacks against our clients. Visits from IP addresses having a history of being used in assaults are treated with suspicion and are more likely to be scrutinized further.
- Behavior analysis – Tracking the ways visitors interact with a website can reveal abnormal behavioral patterns, such as a suspiciously aggressive rate of requests and illogical browsing patterns. This helps identify bots that pose as human visitors.
- Progressive challenges – We use a set of challenges, including cookie support and JavaScript execution, to filter out bots and minimize false positives. As a last resort, a CAPTCHA challenge can weed out bots attempting to pass themselves off as humans.
Learn more about protecting your site from malicious bot traffic with Imperva’s bot management solution.




















