In our previous post in this series we discussed our motivation to cluster attacks on apps, the data we used and how we enriched it by extracting more meaningful features out of the raw data. We talked about the many features that can be extracted from IP and URL. In this blog post we’ll discuss one of the more difficult and important tasks in any clustering algorithm – how to calculate distance.
Measuring Distance Between Attacks
The next thing we need to do is determine a way to calculate the distance between two attacks. This is a core stage of the algorithm, as it determines when two attacks are similar, which in general is what the algorithm is trying to achieve. Calculating a distance between two points in the plane is easy – there is a precise formula to do it – but how can we calculate the distance between two URLs, or two IPs?
We will need to find a method to calculate the distance for every meaningful feature we have in our data. Here we will suggest a couple of methods to do so for certain features where the method is not that trivial. There is no universal truth about which distance method is the best, some work better in certain situations than others.
It is important to note that although we may use a different method to calculate the distance for each feature, we also need all the distances to be on the same scale, otherwise we may have biased results. For example, if two attacks have a distance between 0 and 1 in feature A and between 0 and 100 in feature B it may cause a significant bias in our results. You can’t assume the meaning of feature A distance 1 for both because the distance ratio for feature B is much bigger. If you did, distance 1 for feature B would seem—inaccurately—extremely small.
Here are some methods for calculating distance:
Levenshtein Distance
The need to calculate the distance between two strings is very common for our data, with one of the most notable features being the URL and all the extra features we extracted from it. The Levenshtein distance, which is part of the larger family of edit distance, is a well-known measure to calculate the distance between two strings.
The Levenshtein distance between two strings is the minimum amount of single character edits required to change one string into the other. By edits we mean insertion, deletion or substitution of a single character. See the following example (Figure 1) where the Levenshtein distance between the URL /pictures/cat.jpg to the URL /pictures/dog.jpg is three:

Figure 1: Levenshtein distance is the minimum amount of single character edits required to change one string into the other.
Note that the Levenshtein distance measure is bound above by the length of the longer string. That’s why long URLs tend have higher distances between them than short URLs. In order to reduce this bias we can scale the distance measure to be between 0 and 1 by dividing the distance by the length of the longer string of the two.
Discrete Distance
If x and y are two samples of any data (they can be thought of as two URLs or two countries), then: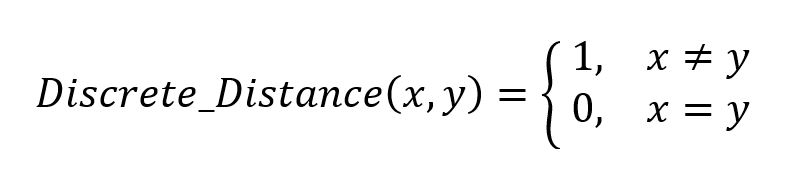 In simple terms, if the two objects are exactly the same, then the distance between them is zero, otherwise it is one. This distance measure might seem simple, even too simple, but in certain situations it works extremely well.
In simple terms, if the two objects are exactly the same, then the distance between them is zero, otherwise it is one. This distance measure might seem simple, even too simple, but in certain situations it works extremely well.
For example, say we want to calculate the distance between two resource extensions of the URL. Many resource extensions are words with three characters (css, php, jpg, etc.) and comparing similarity between two very short words is not always a good option. Also, in this case, different resource extensions usually suggest that the attacks targeted different kinds of pages which might indicate that these are actually two different attacks and shouldn’t be in the same cluster.
Distance Between IPs
Here we only deal with IPV4, which is IP in the format of “number4.number3.number2.number1”, where each number is between 0 and 255. IPV6 has different distance measures that relate to its structure. We suggest a few methods to calculate the distance between two different IPs. The important thing to determine is under what conditions two IPs are similar to each other.
First, consider the condition that two IPs are similar if their numbers are close, where numbers to the right are more significant than numbers to the left. So, for example if we have the following IPs:
IP-1 = 203.132.63.117
IP-2 = 203.132.63.54
IP-3 = 203.134.89.117
IP-1 is closer to IP-2 than to IP-3.
IP as Four-Dimensional Data
An IPV4 consists of four numbers between 0 and 255, then we can think of it as a point in a four-dimensional space. It is easy to calculate the distance between two points in a four-dimensional space, but in our case we also must consider the fact that the numbers to the right are more important than the numbers to the left. Given two IPs:
IP-1 = X4.X3.X2.X1
IP-2 = Y4.Y3.Y2.Y1
We can calculate the distance using a weighted Euclidean distance in the following form:
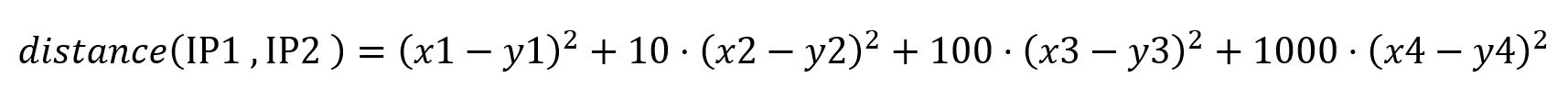
The weights here are 1, 10, 100, 1000, and can be changed to fit the desired result. Different weights can give different scales of data, therefore it is recommended to normalize the distance to have values between 0 and 1. We can also take a square root to make the distance more like a regular Euclidean distance, but it is not necessary.
IP as 32-Dimensional Data
It might seem very convenient to view an IP as a point in a four-dimensional space, but actually it is more coherent to view it as point in a 32-dimensional space. Each IPV4 is represented in 32-bits, because it consists of four numbers between 0 and 255, each of them represented in 8-bits.
For example, the following IP:
IP = 203.132.63.117
Would become:
IP-32bits = 11001011100001000011111101110101
We can utilize this representation to calculate distance between IPs. Let IP1 and IP2 be two IPs in a 32-bit representation, then their distance is:

To explain the mathematical formula in words, we do bitwise XOR between the two IPs and count the leading zeroes (from the left). The distance is 32 minus the number of leading zeroes…then we multiply the result by 1/32 to normalize the distance to be between 0 and 1. This distance measure counts the numbers of identical bits (from the left) the two IPs have.
Although this method may look less intuitive than the previous one, we found it performed a lot better. Also, in this method we don’t have to decide on arbitrary weights and the scaling is very obvious.
IP as Geolocation
It is also possible to view the IP as an exact geographic location using coordinates and calculate the distance between two IPs as the physical distance between the coordinates (see Figure 2).
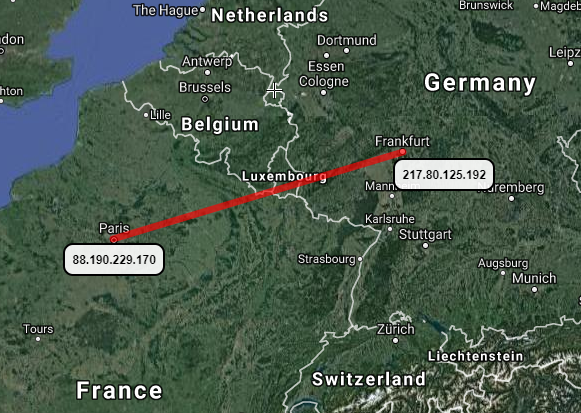
Figure 2: Distance between IPs as geolocation. IP from Paris and IP from Frankfurt.
We found this method less successful than the previous methods described. Instead we used the general geographic location which includes the country and subdivision as separate features from the IP, and calculated the distance between them separately using weighted discrete distance. Here we gave more weight to subdivision than country because two attacks from the same subdivision are much more likely to be similar than two attacks from the same country.
Reducing the Correlation
As you may have noticed, there is a very high correlation between certain features we extracted. For example, two attacks that came from the same IP would also have the same class A, B and C, the same country and the same coordinates. Or when two attacks have the same URL they would also have all the same features we enriched from the URL, this would be even more obvious when the attacks targeted some general URL like the home page of an application.
Having correlation between features may cause bad results if we don’t handle it correctly. That is because two attacks that, for example, target the home page of an application may seem to be identical in many different features related to the URL, although all of these features are correlated to one another! Hence we need to find a way to manage this high correlation between all the features we enriched.
In order to handle this correlation issue we decided to split all the features into context “dimensions”. Each dimension represents a single general attribute of the attack—for example the attack origin, attack tool, the target or the type of attack. Each feature is assigned to a single dimension, so the IP and all its enriched features were assigned to the origin dimension, the URL and its enriched features to the target dimension, etc. Next, we calculated the distance for every feature in the data and gave an aggregated distance for each dimension, where we normalized all the distances of the dimensions to be in the same scale. The final distance is a weighted score between the distances of each dimension. See Figure 3 for some of the dimensions we used.
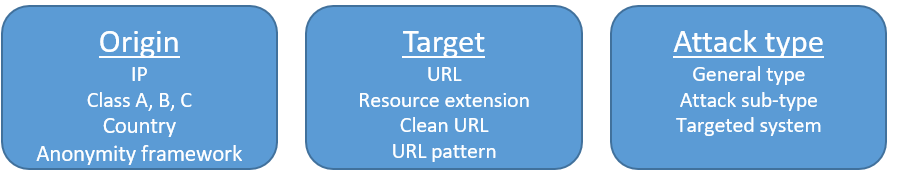
Figure 3: Features split into dimensions – each feature is assigned to a single context dimension. There is no correlation between the different dimensions, only inside each dimension. The final distance is a weighted average of the distances from each dimension.
This method splits the features into dimensions which are entirely uncorrelated with each other. Also, we can give different weights to different attributes of the attack as we see fit based on our knowledge of the domain. For example, we saw in our data that the origin and attack type dimensions are more significant than the target dimension, thus we gave the target less weight in the total calculation.
Next Up: Algorithm Results
To conclude, in this post we discussed one of the core stages of the algorithm – the distance calculation. We explained a couple of methods used to calculate distances between complex features like the URL and IP. Each feature has many different methods to calculate distance, with its own pros and cons, and choosing a best method depends on the specific needs and experiments on test data. Finally we showed a method to reduce the correlation between features using context dimensions. In the next and final post we’ll discuss the clustering algorithm itself. We’ll share how to do clustering in real-time scenarios where only a small amount of data can be stored in memory. And also show application attacks that the algorithm found in actual customers’ data.
Try Imperva for Free
Protect your business for 30 days on Imperva.