What is Buffer Overflow
Buffers are memory storage regions that temporarily hold data while it is being transferred from one location to another. A buffer overflow (or buffer overrun) occurs when the volume of data exceeds the storage capacity of the memory buffer. As a result, the program attempting to write the data to the buffer overwrites adjacent memory locations.
For example, a buffer for log-in credentials may be designed to expect username and password inputs of 8 bytes, so if a transaction involves an input of 10 bytes (that is, 2 bytes more than expected), the program may write the excess data past the buffer boundary.
Buffer overflows can affect all types of software. They typically result from malformed inputs or failure to allocate enough space for the buffer. If the transaction overwrites executable code, it can cause the program to behave unpredictably and generate incorrect results, memory access errors, or crashes.
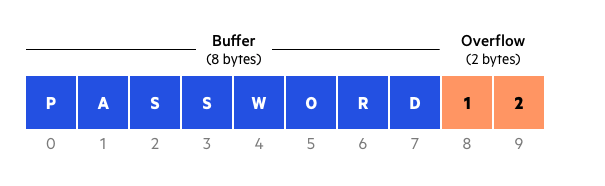
Buffer overflow example
What is a Buffer Overflow Attack
Attackers exploit buffer overflow issues by overwriting the memory of an application. This changes the execution path of the program, triggering a response that damages files or exposes private information. For example, an attacker may introduce extra code, sending new instructions to the application to gain access to IT systems.
If attackers know the memory layout of a program, they can intentionally feed input that the buffer cannot store, and overwrite areas that hold executable code, replacing it with their own code. For example, an attacker can overwrite a pointer (an object that points to another area in memory) and point it to an exploit payload, to gain control over the program.
Types of Buffer Overflow Attacks
Stack-based buffer overflows are more common, and leverage stack memory that only exists during the execution time of a function.
Heap-based attacks are harder to carry out and involve flooding the memory space allocated for a program beyond memory used for current runtime operations.
What Programming Languages are More Vulnerable?
C and C++ are two languages that are highly susceptible to buffer overflow attacks, as they don’t have built-in safeguards against overwriting or accessing data in their memory. Mac OSX, Windows, and Linux all use code written in C and C++.
Languages such as PERL, Java, JavaScript, and C# use built-in safety mechanisms that minimize the likelihood of buffer overflow.
How to Prevent Buffer Overflows
Developers can protect against buffer overflow vulnerabilities via security measures in their code, or by using languages that offer built-in protection.
In addition, modern operating systems have runtime protection. Three common protections are:
- Address space randomization (ASLR)—randomly moves around the address space locations of data regions. Typically, buffer overflow attacks need to know the locality of executable code, and randomizing address spaces makes this virtually impossible.
- Data execution prevention—flags certain areas of memory as non-executable or executable, which stops an attack from running code in a non-executable region.
- Structured exception handler overwrite protection (SEHOP)—helps stop malicious code from attacking Structured Exception Handling (SEH), a built-in system for managing hardware and software exceptions. It thus prevents an attacker from being able to make use of the SEH overwrite exploitation technique. At a functional level, an SEH overwrite is achieved using a stack-based buffer overflow to overwrite an exception registration record, stored on a thread’s stack.
Security measures in code and operating system protection are not enough. When an organization discovers a buffer overflow vulnerability, it must react quickly to patch the affected software and make sure that users of the software can access the patch.
How Imperva Helps Mitigate Buffer Overflow Attacks
The Imperva security solution is deployed as a gateway to your application and provide out-of-the-box protection for buffer overflow attacks. It does so by blocking illegal requests that may trigger a buffer overflow state, preventing them from reaching your applications.
In addition to protecting against buffer overflow attacks, Imperva provides multi-layered protection to make sure websites and applications are available, easily accessible and safe. The Imperva application security solution includes:
- DDoS Protection—maintain uptime in all situations. Prevent any type of DDoS attack, of any size, from preventing access to your website and network infrastructure.
- Web Application Firewall—permit legitimate traffic and prevent bad traffic. Safeguard your applications on-premises and at the edge with an enterprise‑class cloud WAF.
- Bot Management– get full visibility and control over human, good bot, and bad bot traffic to your website and API.
- Account Takeover Protection—uses an intent-based detection process to identify and defends against attempts to take over users’ accounts for malicious purposes.
- API Security—protects APIs by ensuring only desired traffic can access your API endpoint, as well as detecting and blocking exploits of vulnerabilities.
- RASP—keep your applications safe from within against known and zero‑day attacks. Fast and accurate protection with no signature or learning mode.
- Attack Analytics—mitigate and respond to real security threats efficiently and accurately with actionable intelligence across all your layers of defense.